Storing data
Datasets are
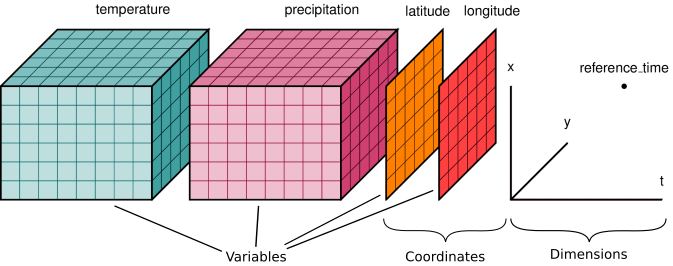
(from xarray docs)
- n-dimensional variables
- shared dimensions
- coordinates
- attributes for metadata
Access to subsets
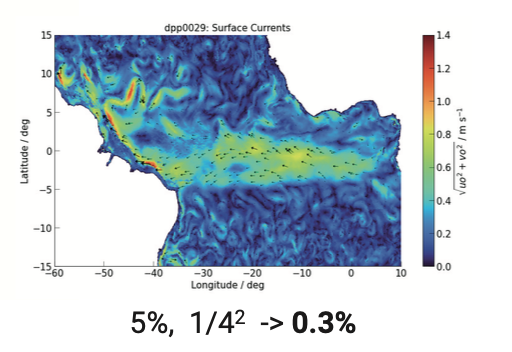
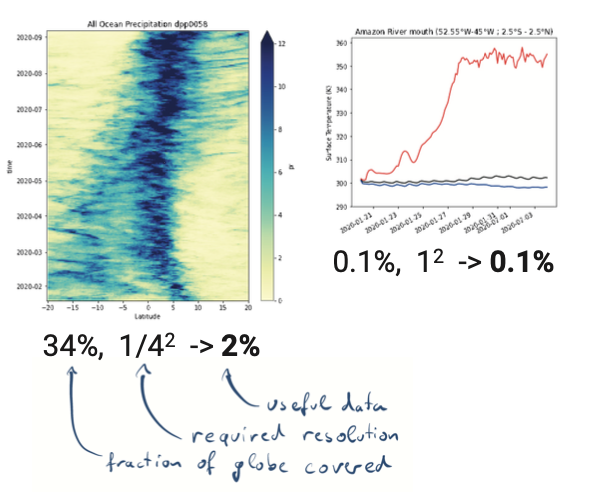
Without subset access and hierarchies, analysis scripts are forced to load way too much data.
Align the ordering of data with read patterns

https://www.unidata.ucar.edu/blogs/developer/entry/chunking_data_why_it_matters
Make a compromise that’s okay-ish for everybody by chunking along all dimensions.
