Building useful datasets for
Earth System Model output
2024-10-20
datasets are
(for this talk)
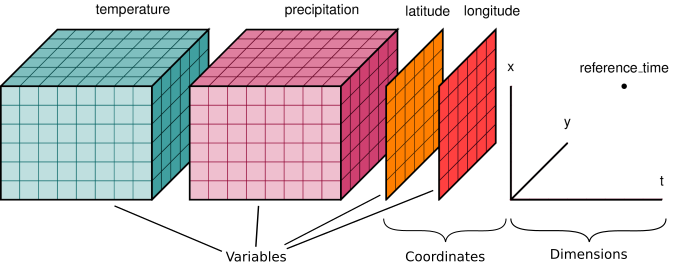
figure from xarray documentation
- n-dimensional variables
- shared dimensions
- coordinates
- attributes for metadata
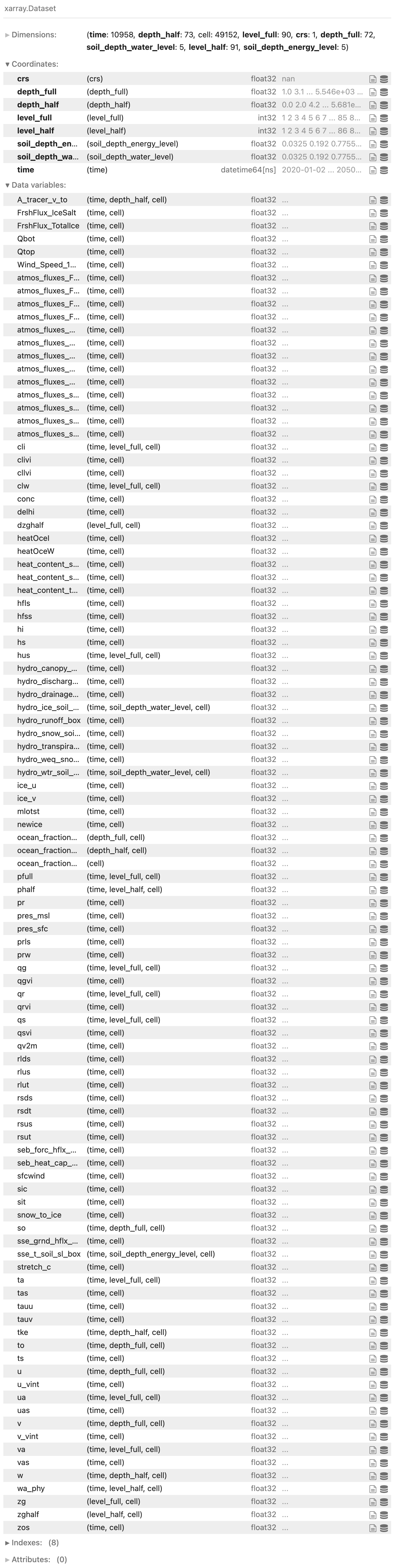
now: a single dataset
different regions, same size
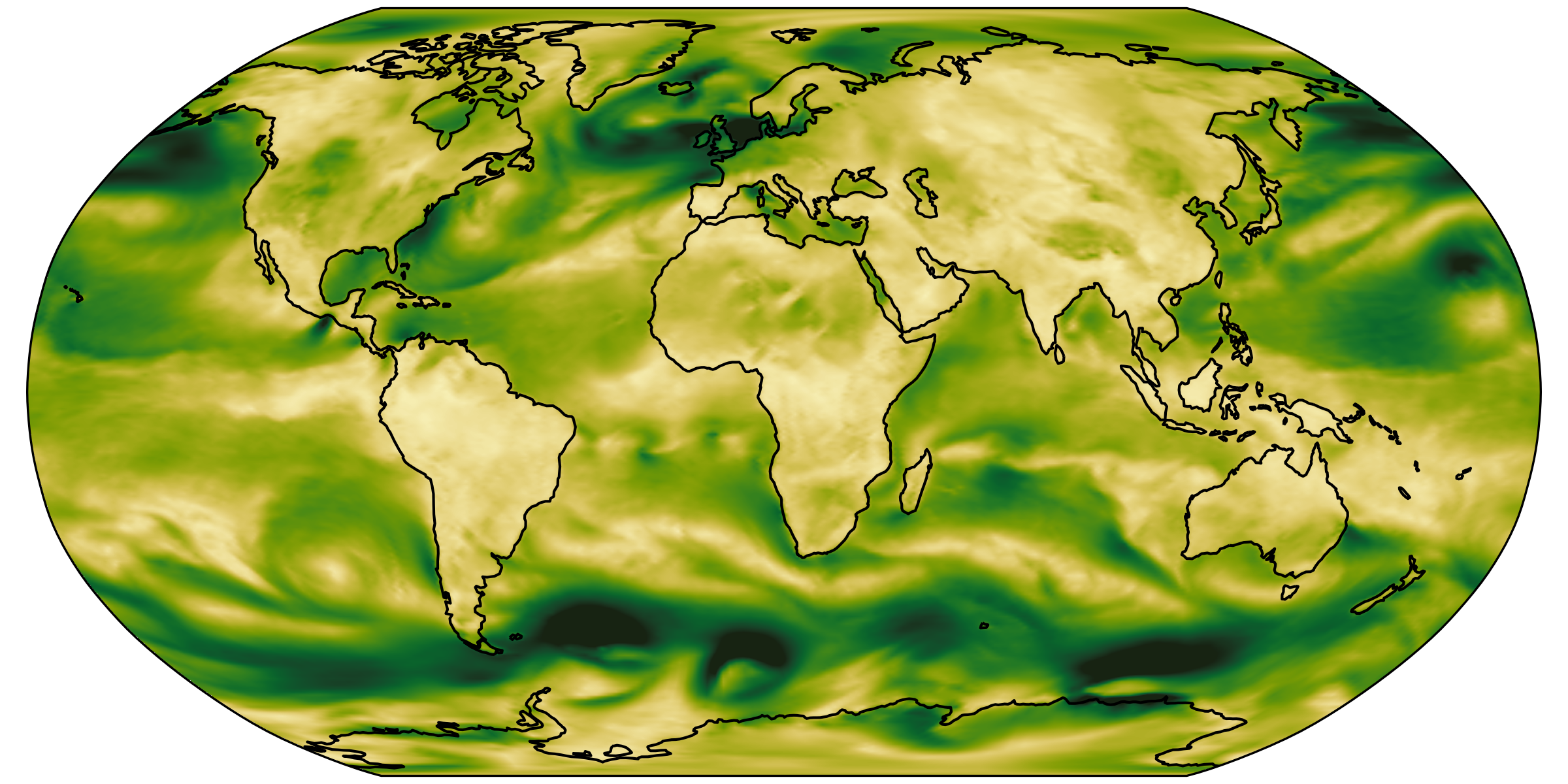
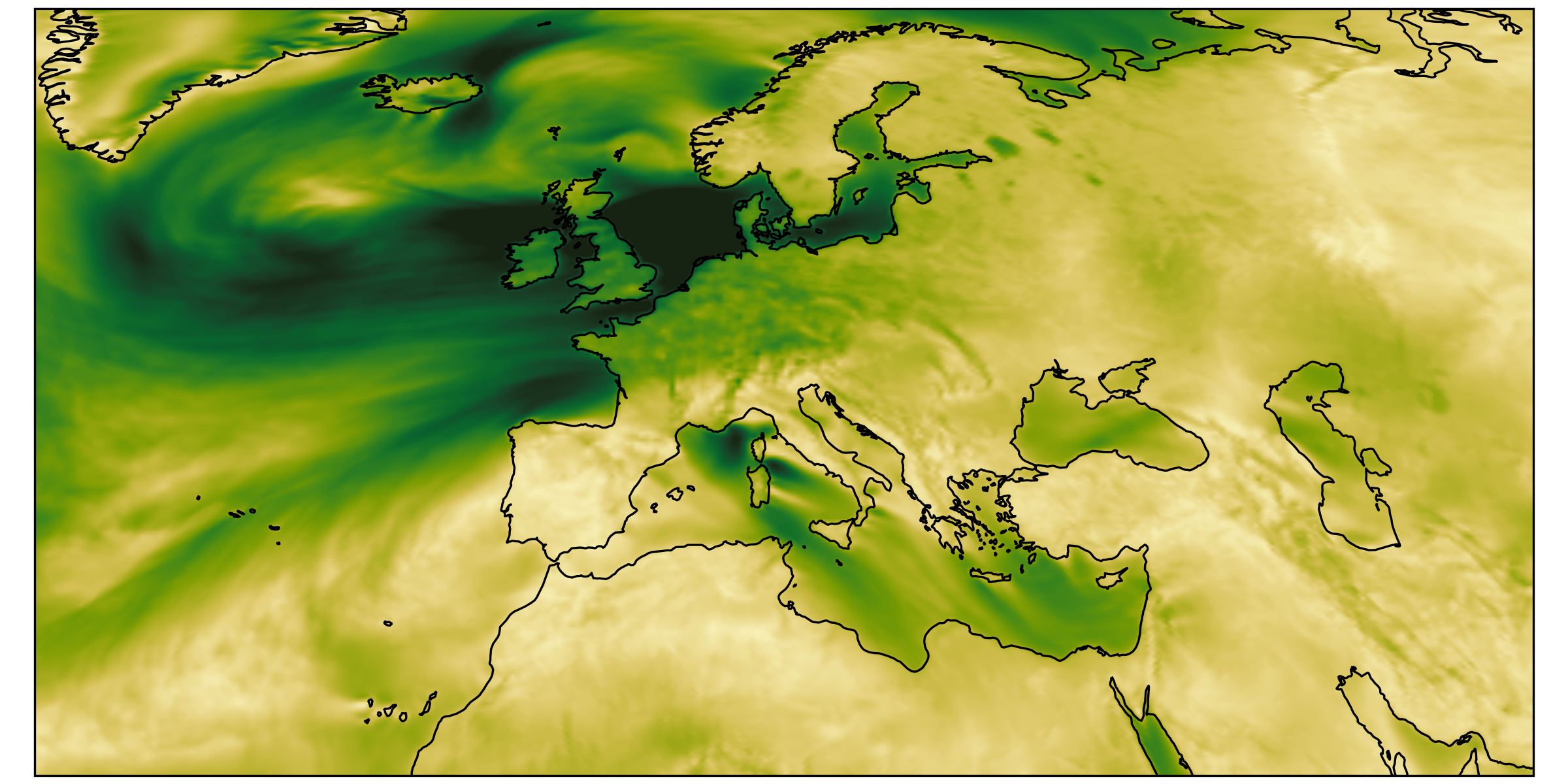
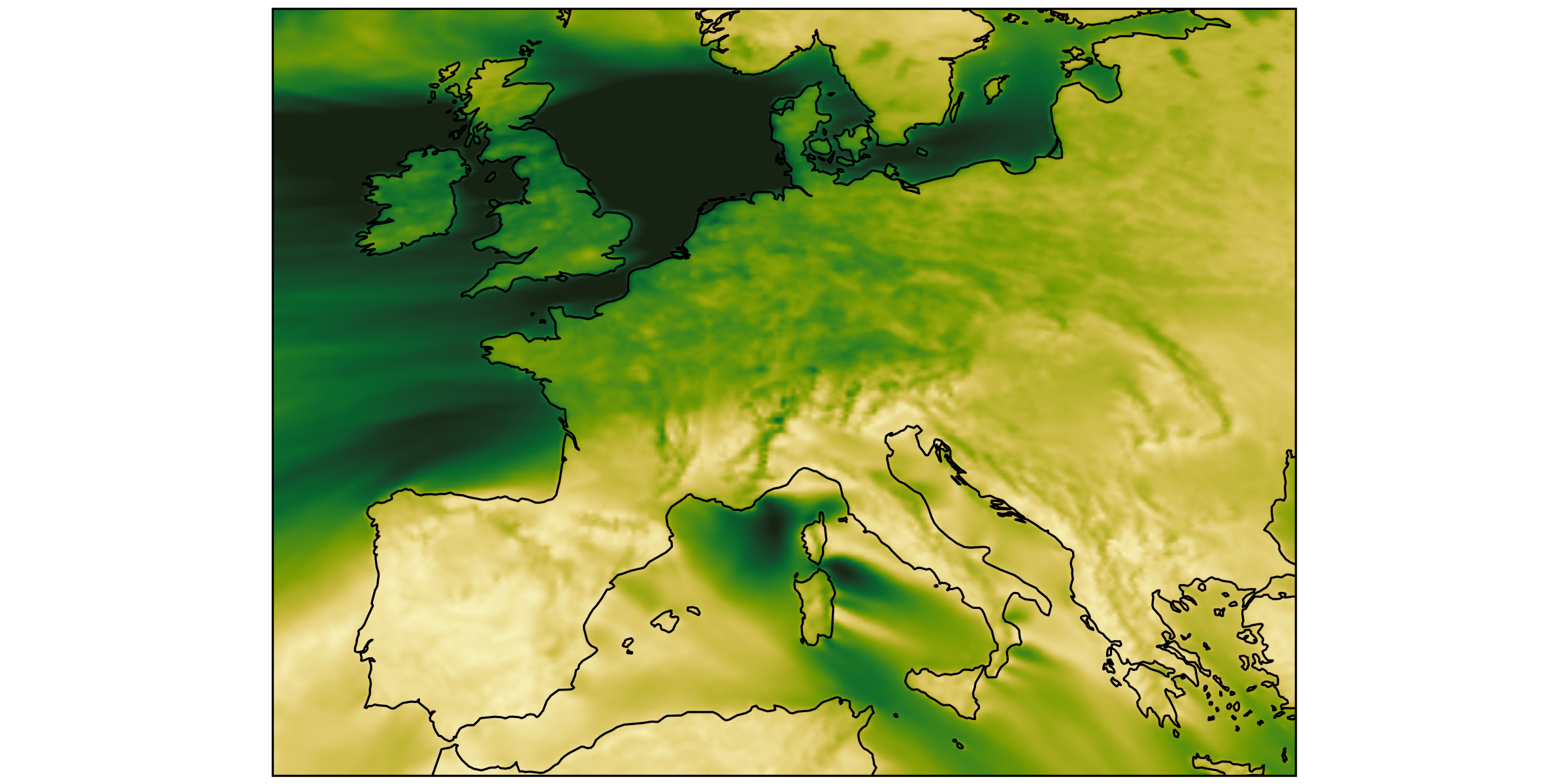
we had: over-loading
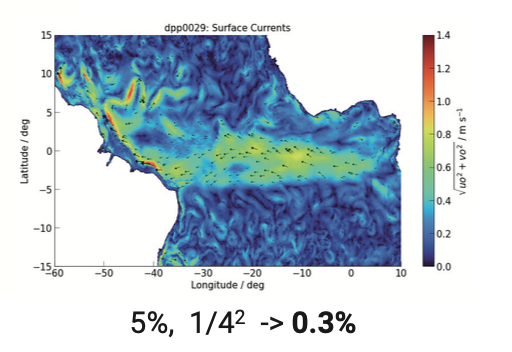
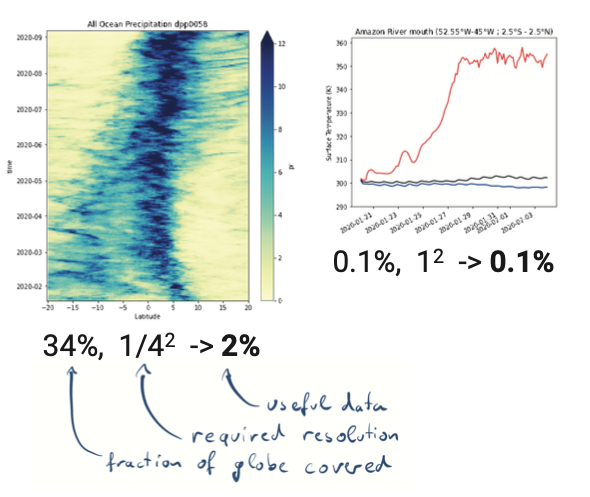
Analysis scripts are forced to load way too much data.
Plots by Marius Winkler & Hans Segura
now: aggregation

now: chunking
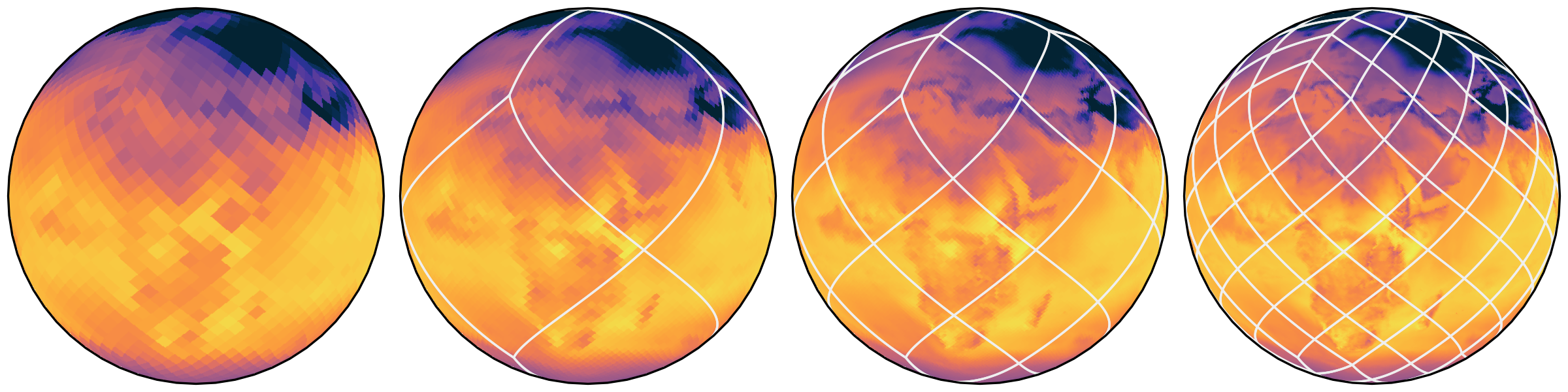
about HEALPix
- Hierarchical
- Equal Area
- isoLatitude

Not necessary for the aforementioned.
… but aligns very well.
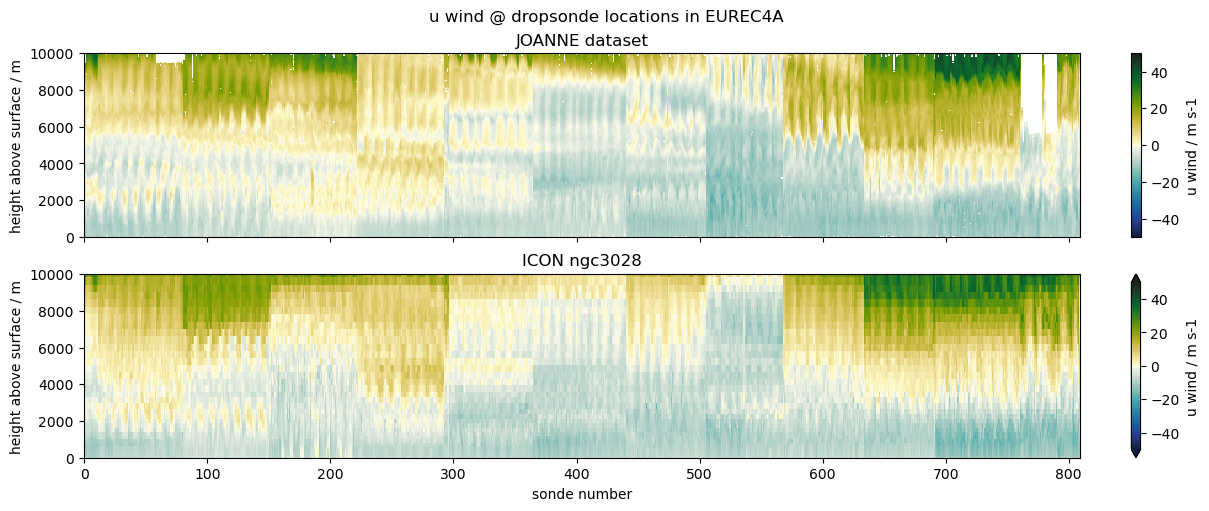
dropsonde vs model
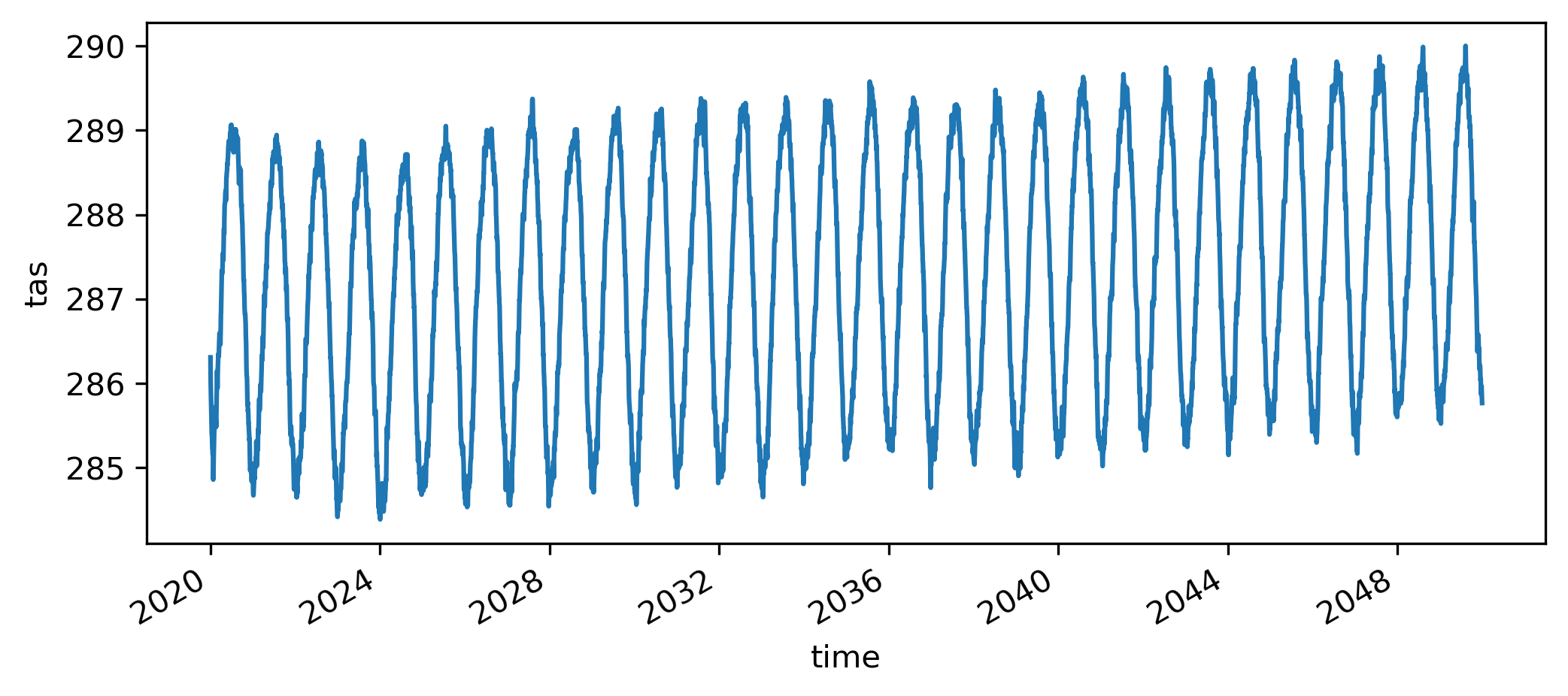
monitoring
(100ms, 250MB, single thread)
